(en Ingles: Extension Methods)
La semana pasada empecé una serie de post en el blog en los que cubriré algunas de las nuevas características de VB y C# que van a venir con la nueva release de Visual Studio y el .NET Framework.
En mi último post hablé sobre las Propiedades Automáticas, Inicializadores de Objetos e Inicializadores de Colecciones. Si aún no lo habéis leído, podéis leerlo aquí. El post de hoy va sobre una nueva característica que viene tanto en VB como en C#. Métodos de extensión.¿Qué son los métodos de extensión?
Los métodos de extensión permiten a los desarrolladores añadir nuevo métodos al contrato público de un tipo ya existente en el CLR, sin tener que recompilar el tipo original. Los métodos de extensión permiten mezclar la flexibilidad del soporte “duck typing” de los lenguajes dinámicos de hoy con el rendimiento y la validación en tiempo de compilación de los lenguajes fuertemente tipados.
Los métodos de extensión posibilitan la aparición de una gran variedad de escenarios , y ayudan a hacer posible el poder del framework LINQ que va a ser añadido a .NET como parte de la release de Orcas.
Ejemplo de un método de extensión simple:
¿No habéis querido chequear si un string es una dirección válida de email? Hoy, implementaríamos esto llamando a una clase a parte (seguramente con un método estático) para ver si el string es válido. Por ejemplo, algo así:
string email = Request.QueryString[“email”];if ( EmailValidator.IsValid(email) ) {
}
Usando métodos de extensión podríamos añadir un método “IsValidEmailAddress()” dentro de la propia clase string, y devolverá cierto o falso dependiendo de si la dirección es válida o no. De esta forma, podríamos hacer lo de arriba con el siguiente código:
string email = Request.QueryString[“email”];if ( email.IsValidEmailAddress() ) {
}
Pero, ¿cómo añadimos este nuevo método, IsValidEmailAddress(), a la clase string?. Lo hicimos definiendo una clase estática con un método estático que contiene nuestro método de extensión IsValidEmailAddress() de la siguiente forma:
public static class ScottGuExtensions
{
public static bool IsValidEmailAddress(this string s)
{
Regex regex = new Regex(@”^[w-.]+@([w-]+.)+[w-]{2,4}$”);
return regex.IsMatch(s);
}
}
Daros cuenta que en el parámetro de entrada del método está la palabra “this”, antes que el parámetro de tipo string. Esto le dice al compilador que este método de extensión debe ser añadido a objetos de tipo string. Dentro del cuerpo del método IsValidEmailAddress() podemos acceder a todas las propiedades/métodos/eventos públicos de la instancia del string actual, y devolver true/false dependiendo de si es un email válido o no.
Para añadir este método de extensión específico a las instancias de string de mi código, sólo usamos un “using” estándar para importar el namespace que contiene la implementación de los métodos de extensión:
using ScottGuExtensions;
El compilador resolverá correctamente el método IsValidEmailAddress() en cualquier string. C# y VB dan soporte completo para el intellisense de los métodos de extensión en el editor de Visual Studio. De manera que cuando pulsamos el “.” en una variable string, los métodos de extensión que hayamos implementado, se mostrarán en la lista del intellisense.

Los compiladores de VB y C# dan soporte para el chequeo en tiempo de compilación del uso de métodos de extensión.
[Creditos: Gracias a David Hayden por su primera aproximación al escenario de IsValidEmailAddress de ántes por su post sobre el tema el año pasado.
Continuación de los escenarios para métodos de extensión…
Centrándonos en los métodos de extensión para añadir métodos a tipos existentes, podemos abrir una gran variedad de escenarios posibles para los desarrolladores. Lo que realmente hace a los métodos de extensión una herramienta prodigiosa no es sólo poder ser aplicada a tipos individuales, sino a cualquier clase padre o interface del .NET Framework. Esto permite a los desarrolladores construir una variedad casi infinita de extensiones que se pueden usar en todo el .NET Framework.
Por ejemplo, imaginemos que quiero comprobar de forma fácil y descriptiva si un objeto está añadido en una colección o array de objetos. Podemos añadir un simple método de extensión .In(collection) que quiero que se añada a todos los objetos de .NET para poder hacer eso. Podemos implementar este método de extensión “In()” en C# de la siguiente forma:

Fijaos cómo he declarado el primer parámetro para el método de extensión es “this object o”. Esto indica que este método de extensión debe ser aplicado a todos los tipos que hereden de la clase base System.Object – esto significa que puedo usar este método en cualquier objeto en .NET.
La implementación del método “In()” de arriba, nos permite ver si un objeto específico está incluido en una secuencia IEnumerable que se le pasa como argumento. Debido a que todas las colecciones de .NET implementan la interfaz IEnumerable, hemos conseguido un método útil y descriptivo para comprobar si cualquier objeto de .NET pertenece a cualquier colección o tabla de .NET.
Podemos usar este método de extensión “In()” para comprobar si un string en particular está en un array de strings:

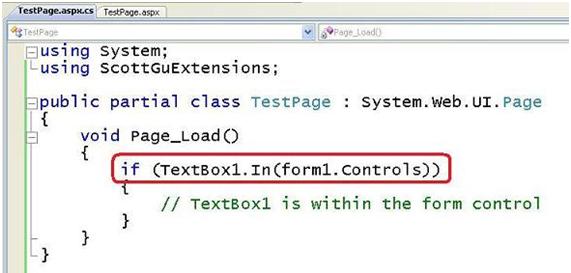
Incluso podemos comprobar si un control de ASP .NET está en un contenedor de controles:

Hasta podemos usarlos con tipos escalares como enteros:

Daos cuenta de que podemos usar estos métodos de extensión hasta en valores de los tipos base (como el entero 42). Ya que el CLR soporta el boxing/unboxing automático de clases valor, los métodos de extensión se pueden aplicar a números y otros tipos de datos escalares directamente.
Como podéis empezar a discernir de los ejemplos de arriba, los métodos de extensión nos abren escenarios muy ricos y posibilidades de extensibilidad. Cuando se aplican a clases comunes y a interfaces en .NET nos habilitan frameworks de dominio específicos muy curiosos.
Sistema empotrado. Métodos de extensión de Linq.
Una de las librerías de métodos de extensión que estamos metiendo en .NET en Orcas, son un conjunto de métodos de extensión que permiten a los desarrolladores hacer consultas sobre datos. Estas implementaciones están en el namespace “System.Linq”, y definen un sistema de consultas estándar para ser usado por cualquier desarrollador de .NET para consultar archivos XML, bases de datos relacionales, objetos .NET, y/o otro tipo de estructura de datos.
Algunas de las ventajas de usar el modelo de extensibilidad de consultas son:
1) Provee un modelo de programación de consultas y una sintaxis que puede ser usada para todos los tipos de datos (bases de datos, archivos XML, objetos en memoria, servicios web, etc).
2) Permite a los desarrolladores añadir nuevos métodos y operadores en la sintaxis de las consultas. Por ejemplo: podríamos usar nuestro método “In()” junto al estándar “Where()” definido por LINQ como parte de una consulta simple. El método “In()” parecerá tan natural como los métodos “estándar” en el namespace System.Linq.
3) Es extensible y permite que podamos usar cualquier tipo de proveedor de datos. Por ejemplo: un motor ORM como NHibernate o LLBLGen podrían implementar los operadores del estándar LINQ para permitir consultas LINQ en esas implementaciones de ORM y motores de mapeo. Esto permitirá a los desarrolladores aprender una forma común de consultar datos, y aplicar las mismas habilidades sobre una gran variedad de implementaciones de salvaguarda de datos.
Escribiré mucho sobre LINQ en las próximas semanas, pero quería dejaros un par de ejemplos para mostrar cómo usar alguno de los métodos de LINQ con diferentes tipos de datos:
Escenario 1: Usando Linq sobre objetos de .NET en memoria.
Supongamos que hemos definido la clase “Person” de la siguiente manera:

Podemos usar los nuevos inicializadores de objetos y de colecciones para crear una colección “people” así:

Podríamos usar el estándar “Where()” de LINQ para obtener una secuencia de los objetos de tipo “Person” cuyos nombres empiezan por S:

La nueva sintaxis => es un ejemplo de las expresiones Lambda, que son una evolución de los métodos anónimos de C# 2.0, y nos permite expresar fácilmente un filtro con un argumento (en caso de que estemos indicando que sólo queremos devolver una secuencia con los objetos Persona cuya propiedad FirstName empiecen con la letra “S”). La consulta anterior devolvería 2 objetos como parte de la Secuencia (por Scott y Susanne).
Podemos escribir un código que use las ventajas de los métodos “Average” y “Max” que nos aporta System.Linq para determinar el promedio de edad de nuestra colección de personas, así como la edad mayor:

Escenario 2: Usando LINQ sobre archivos XML
Probablemente sea raro que creemos una colección de datos en memoria manualmente. Lo más común es que obtengamos esos datos de un archivo XML, una base de datos o un servicio web.
Supongamos que tenemos un archivo XML en el disco con los siguientes datos:

Obviamente podemos usar la API de System.XML para cargar el archivo en un DOM y acceder a él, o usar la API XmlReader para parsearlo manualmente. Pero con Orcas podemos usar la implementación de System.XML.Linq que soporta el estándar de extensión de métodos LINQ para parsearlo y procesarlo más elegantemente.
El código de abajo nos muestra cómo usar LINQ para obtener todos los objetos de los elementos XML <person> que tienen un subnodo <person> cuyos valores internos empiezan con la letra “S”:

Daos cuenta que su uso es igual que el método de extensión Where() del ejemplo del objeto en memoria. Ahora vamos a devolver una secuencia de elementos “XElement”, un tipo no-tipado de un nodo XML. Podemos reescribir la consulta de forma que nos devuelva los datos usando el método Select() de LINQ y crear una expresión Lambda que use la sintaxis de inicializadores de objetos para calcular la misma clase “Person” que usamos en el primer ejemplo:

El código anterior hace todo el trabajo necesario para abrir, parsear y filtrar el XML del archivo “test.xml”, y nos devuelve una secuencia fuertemente tipada de objetos Person. No hace falta ningún mapeado para los valores – estamos expresando la transformación XML -> objeto directamente con la consulta de LINQ.
Incluso podríamos usar los mismos métodos de LINQ: Average() y Max() para calcular el promedio de edad de los elementos <person> del archivo XML y la mayor edad:

No tenemos que parsear manualmente el archivo XML. No sólo XLINQ hará esto por nosotros, sino que además parseará el archivo usando XMLReader y no tendrá que crear un DOM para evaluar las expresiones de LINQ. Esto se traduce en mayor velocidad y bajo consumo de memoria.
Escenario 3: Usando LINQ sobre bases de datos.
Supongamos que tenemos una base de datos que contiene una tabla llamada “People” y que tiene el siguiente esquema:

Podemos usar el nuevo diseñador LINQ to SQL WYSIWYG ORM de Visual Studio para crear rápidamente una clase “Person” que mapee la base de datos:

Podemos usar el mismo método de LINQ Where() que usamos para los objetos y el XML para obtener una secuencia fuertemente tipada de objetos “Person” de la base de cuyo nombre comience por “S”:

Fijémonos en que la sintaxis es la misma que la de los objetos en memoria y para el archivo XML.
Podemos usar los métodos de LINQ: Average() y Max() para obtener el promedio y la edad máxima:

No hay que escribir ningún código SQL. El mapeador relacional LINQ to SQL que viene con Orcas se encargará de obtener, rastrear y actualizar objetos que se mapeen con el esquema de nuestra base de datos y/o SPROC’s. Podemos usar LINQ para filtrar los resultados, y LINQ to SQL ejecutará el código SQL necesario para obtener los datos (Nota: Los métodos Average y Max no devolverán todas las filas de la tabla, obviamente – sino que usara las funciones necesarias de TSQL para calcular los valores de la base de datos y devolver resultados escalares).
Ved este video que gravé en Enero para ver cómo LINQ to SQL aumenta la productividad de datos en Orcas. En el video también podéis ver el nuevo diseñador LINQ to SQL WYSIWYG ORM en acción, así como el intellisense del editor de código cuando escribimos código LINQ sobre el modelo de datos.
Resumen
Este post nos da una base para entender cómo funcionan los métodos de extensión, y algunas de las cosas que se van a poder hacer con él. Como cualquier método de extensibilidad, no he querido saturaros creando nuevos métodos de extensión. Y es que, ¡aunque tengas un nuevo martillo no significa que todo en el mundo se haya convertido en una nuez.!
Si os queréis iniciar probando métodos de extensión os aconsejo que le echéis un vistazo a los operadores estándar de consultas que vienen en System.Linq en Orcas. Nos dan soporte sobre arrays, colecciones, stream de XML, o bases de datos, y pueden incrementar extraordinariamente vuestra productividad cuando trabajáis con datos. Os daréis cuenta de que reducirán significativamente la cantidad de código que tenéis que escribir en vuestras aplicaciones, y os permitirá escribir código limpio y descriptivo. También tendréis intellisense automático y checking en tiempo de compilación de consultas lógicas en vuestro código.
En las próximas semanas seguiré esta serie de post en las características de tipos anónimos e interfaces anónimas, y seguiré hablando sobre Lambda y otra cosas. Obviamente hablaré un montón sobre LINQ.
Espero que os haya gustado.
Scott.
Traducido por: Juan María Laó Ramos. Microsoft Student Partner.