Hace algún tiempo que en el podcast de Aporreando Teclados hemos hablado bastante sobre Agile. Y no es raro que caigan en nuestras manos libros como “Actionable Agile Metrics for Predictability” y” When Will It Be Done” de Daniel S. Vacanti.
Spoiler:
El autor nos indica que la lista de tareas realizadas en un proyecto de software es un generador de números aleatorios. Basta con monitorizar dos cosas:
- El día en que se empieza a trabajar en esa tarea
- El día en que se da por cerrada esa tarea
A partir de esas dos fechas, puedes obtener el número de días en las que se ha trabajado. Hace notar que si una tarea empieza y termina el mismo día, no significa que se haya tardado en cerrar cero días, sino que ese caso es un día, aunque haya sido una, dos u ocho horas. Con esto podemos obtener una tabla como la del ejemplo:
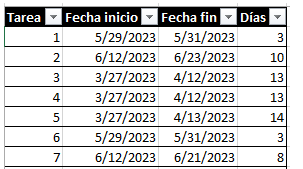
En la obra se explica que la columna de Días son números totalmente aleatorios con una sutileza: Son aleatorios sí, pero indican lo que ha ocurrido en la realidad. Y eso es lo importante, ya que con esta información se puede saber algo muy importante:
Cycle Time o tiempo en el que se tarda desde que se empieza una tarea hasta que finalmente se termina.
Una imagen vale más que mil palabras
Esta información podemos visualizarla de una forma más amigable, usaremos un gráfico de dispersión (Scatter plot). En el eje horizontal se muestra el devenir de la vida (el tiempo) y en el eje vertical el Cycle Time de todas las tareas:
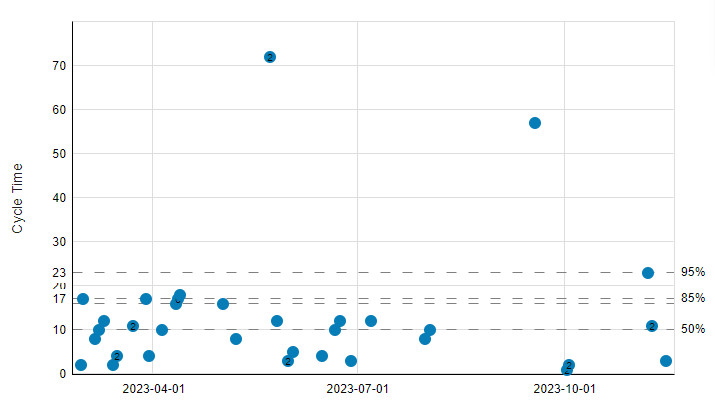
Se han marcado diferentes percentiles teniendo en cuenta toda la información de lo que ha pasado en realidad: 95, 85, 50. ¿Porqué?
Los Percentiles
Una primera observación es que parece que hay más tareas por encima del percentil 50 que por debajo. Es decir, hay más tareas que tardan en cerrarse más de 10 días que menos. Por tanto, si nuestros sprints son de 2 semanas, es decir de 10 días, ¿tiene sentido ese tamaño de sprint?
Si en ese sprint decimos que vamos a hacer una tarea, da igual los puntos de historia que tenga, tenemos una probabilidad más alta de NO terminarla que de terminarla.
¿Qué acción podemos tomar? Subir el tamaño de los sprints a … 17 días que es lo que nos está indicando el percentil 85 sería una opción.
Con esto, dada cualquier tarea que añadamos al sprint, tendríamos un 85% de probabilidades de terminarla.
Esta decisión de incrementar el tamaño del sprint es cosa de cada uno, y para nada estoy sugiriendo que la regla sea: el tamaño del sprint debe estar en el percentil 85. Un sprint de 17 días suena raro, muy raro.
Datos más datos
Una segunda observación es que hay dos puntos que están muy lejos del percentil 95. Podríamos decir que son “outliers” u “outsiders” y no hacerles mucho caso, pero eso es un error. Por muy alejados que estemos del percentil 95, esos puntos son hechos reales que han ocurrido con esas tareas. Y ya en los libros nos adelanta que las predicciones serán tan buenas como buenos sean los datos de los que partimos, si quitamos esos outsiders, quitamos bastante información.
¿Puedes imaginar una predicción meteorológica en la que no se tenga en cuenta el tiempo que hizo ayer? De hecho, es un ejemplo con el que parte el segundo libro, When Will It Be Done, y es que es necesario conocer toda la información anterior para poder hacer una predicción.
Pero una predicción no es lo que va a ocurrir, sino lo que va a ocurrir con cierta probabilidad.
Simulando que es gerundio
El libro no va sobre cómo hacer simulaciones, eso ya se estudia y ha demostrado su valía en la predicción meteorológica e incluso en los experimentos realizados en Los Alamos mientras se creaba la primera bomba nuclear. El sistema que se usa es “Simulación Monte Carlo” pero este humilde blog tampoco se va a centrar en cómo se hace, ya que lo que nos importa es la información que esas simulaciones nos van a proporcionar.
Para los datos del ejemplo, esta simulación, iterada 10.000 veces, para intentar predecir cuándo se terminarán 20 tareas más nos da el siguiente resultado:
- Con un 50% de probabilidad, las 20 tareas estarán el 14 de Marzo de 2024
- Con un 70% de probabilidad, las 20 tareas estarán el 2 de Abril del 2024
- Con un 85% de probabilidad, las 20 tareas estarán el 21 de Abril del 2024
- Con un 95% de probabilidad, las 20 tareas estarán el 16 de Mayo del 2024
Curiosidad
Fijaos que no hemos hablado de tamaño de tareas ni nada por el estilo; por tanto, da igual si están estimadas o no esas tareas, la realidad al final siempre se acaba imponiendo, y parece que no tiene sentido estimar las tareas, ojo, para un proyecto en marcha, con varios sprints a sus espaldas.
Aunque parezca mentira, no hace falta usar mucha información para empezar a hacer estas simulaciones, tendría que leer otra vez los libros, pero me resuena en la cabeza que con 11 mediciones de tareas que hayas realizado suele ser suficiente para empezar.
A medida que vayamos avanzando en nuestro proyecto, cerrando tareas, estas simulaciones deben ir rehaciéndose. Como la predicción del huracán que decía al principio, cada día que pasa hay que ir actualizando la predicción.
Ganando pasta
Haciendo de décimo hombre, y criticar por criticar, los libros parecen un panfleto publicitario de la herramienta que usan para hacer estos cálculos, que tenéis disponible en https://actionableagile.com/ (Las capturas de pantalla y las simulaciones que he hecho se han sacado de ahí con el plan free)
Los libros y este post son una lista de puntos de porqué debemos empezar a medir ese cycle time, hacer simulaciones y actuar en consecuencia con la información real que tenemos lo antes posible.
Espero que os sirva.


